

It seems with the rise of a new technology, it soon follows on the discussion on how to standardize it. This is true for open data and the call for standards of key data sets where data on a particular topic would share the same schema across cities, states, counties, and countries. The promise is civic apps, which help bring data from rarefied portals to every day people, could be built-once and used-everywhere (“frictionless”). This provided a tremendous value for governments who can see the value in their work for open data. Standards on building inspections, food inspections, parks/trails, and social service directory have been proposed.
There is good reason to believe this can be useful. The GTFS data standard (initially Google Transit Feed Specification then dubbed General Transit Feed Specification) unified bus and train directions that was into Google Maps and other programs. The integration made it possible to use Google Maps to get directions to a location with public transportation. But for most topics, open data standards will not provide the same benefit. While open data standards promise a better experience with apps that can easily connect to multiple portals, they will ultimately degrade the user experience for non-technical users unless some approaches to open data are fundamentally changed.
First, open data standards often rely on relational data models. For instance, data standards for inspections would depend on multiple tables: an inspection table, a table listing entities/business/buildings, a violation table, and so on.
HDScores for food inspections
But data portals do not handle relational data very well. So, as a result, a relational structure requires the first step to download or view all tables to be combined in an external program or programming language. While developers and programmers can handle those steps, it is significantly harder for non-technical users. Open Data has, rightly, been criticized for being too technical and this would not make it easier.
This puts user friendliness at conflict with the promise of universal, frictionless apps. The former provides immediate usefulness to a non-programmer where as the latter as a promise for user friendliness. Programmers though have proven to be quite adept at handling differences in schemas. Apps like HDScores, Look at Cook, Plenario/OpenGrid (disclosure: a project I’ve led), and others are able to get around this issue.
Data portals need to serve multiple audiences so the format needs to be both accessible to technical and non-technical audiences. Often, that leads to a format that tries to be readable as a spreadsheet (i.e., every row is a violation) and useful for a programmer. That often results in a “flat” format that can includes a lot of columns. These are obviously not ideal, normalized schemas, but are able to strike a balance for all audiences.
GTFS is an excellent example for the usefulness of data standards. However, GTFS is unique since it has existed purely as a technical specification since its inception. Bus and train schedules have been readily available as maps and people did not rely on machine-readable formats. But data such as business licenses, crimes, salaries, and more have been useful in their “spreadsheet” format. Moving to a relational model for these topics would degrade the experience while gambling on the hope for user-friendly apps.
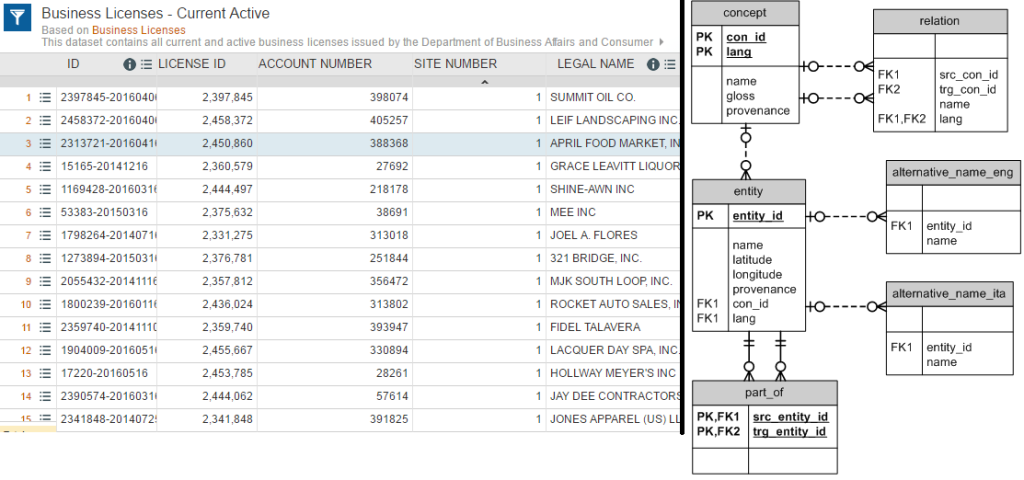
Neither are perfect, but portals can serve programmers and non-technical users better than a relational schema
Flexible solutions, such as RDF/RDFa/schema.org have not been able to gain traction in the larger web development community, so also unlikely to gain traction in open data.
Finally, the development of schemas has lagged the publication of data in most cases. Working to release a standard schema requires work. For existing open data, that means conforming data to a standard, communicating with developers, and making the transition to a new schema. When facing a decision on publishing more data or re-releasing data in a different schema, I believe the movement should still focus on expanding transparency and adding more open data.
Of course, each one of these concerns can be addressed:
- Portals could better-accommodate data standards by allowing technical users to access the relational schema through the API while providing a unified interface for non-technical users. That will help provide full technical robustness with user friendliness.
- Focus a few hackathons to focus the transition of existing data into data standards (a “FTFY” solution with the public)
- It could be easier to publish these through “off-the-shelf” ETLs. Many cities use similar programs for “big” topics like inspections, financials, 311, etc. Reducing ETL development allows for less time spent on (re)-writing ETLs to permit growth of portals and releasing as standards.
And that’s the hope behind data standards for open data. While there are structural issues that need to be resolved before standards can take hold, there are potential solutions available that just require some work to complete. This is a partial list of concerns, but other concerns–such as definitions of items, like “violation”, are not the same across cities–are not a crucial.
Fortunately, there is a robust conversation on data standards for open data. I hope they can be resolved in order to advance open data.
Sounds like what we need are versioned data standards (which APIs handle fairly well) and public facing “flat formats” that make it easy for John Q Public to access. This is a slight riff on your recommendations above, but gives a clearer path for making incremental progress before having to agree on The Standard.
Question for the crowd and author…do you think if Google were not involved we would have a well-adopted transit feed (de-facto) standard? One wonders if wide-scale success can happen without the lure of consumer-friendly access that a Google-like solution delivers. Can governments incentivize the big 4 dot.coms to advance other content like food premise inspections? The disconnect for Open Data between ->no standards->standards->adoption could well prevail for another decade otherwise. Is this an unfortunate but realistic perspective?
Duncan-
I think that is a possible idea. GTFS is a great example of how data standards work. But based on other experience, sometimes data standards offered by start-ups do not work. Namely, the standards may only be useful insofar as supporting the company’s specific goals. Often, those standards–because it was proposed by a single company–may not be adopted by anyone else. A standard needs the network effect to gain momentum. I would feel more optimistic if a few companies proposed any standard. So far, it seems that Google’s ability to single-handed shepherd the GTFS is the exception that proves the rule.
I don’t think governments should be in the role of trying to incentivize these companies to create standards. Instead, if there is value to standards, I would expect hope the companies could work together to propose a standard that proves useful.